Alibaba Leads RMB 2 Billion Series B to Support General World Model Development
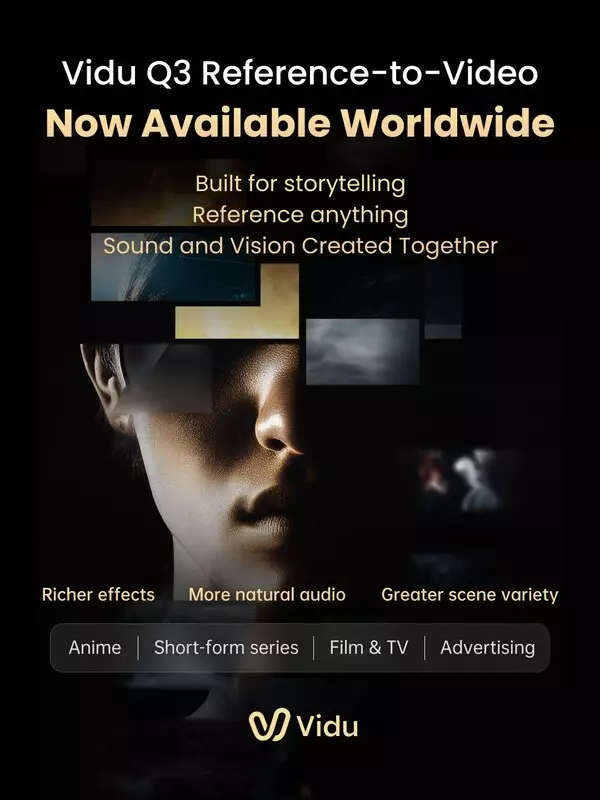
SINGAPORE, April 13, 2026 /PRNewswire/ -- ShengShu Technology, a global leader in multimodal generative AI, today announced the global launch of Vidu Q3 Reference-to-Video, a new model capability designed for story-driven video creation through flexible reference-based generation.
Built for storytelling, Vidu Q3 Reference-to-Video enables creators to generate high-quality videos by referencing and combining a wide range of inputs—including subjects, environments, costumes, props, and visual styles—within a single workflow, significantly improving creative control, consistency, and efficiency.
The release expands capabilities across visual effects, audio, and scene composition. It supports six types of cinematic visual effects, including particle systems, fluid simulation, dynamic motion, camera movement, transitions, and lighting, enabling more expressive visual outputs. In parallel, the model enhances audio generation with five categories of sound capabilities for more natural and expressive results, covering ambient sound, motion-driven audio, atmospheric layers, foley effects, and emotion-driven cues. Together, these improvements enable greater scene diversity and more immersive, production-ready video outputs.
Designed for use cases including short-form series, animation, film and television, as well as advertising and e-commerce, Vidu Q3 Reference-to-Video enables faster production of high-quality video content for both creators and enterprises. This performance is further reflected in third-party benchmarks, where Vidu Q3 ranked No.1 in the first global Reference-to-Video leaderboard released by SuperCLUE.
Built on the Vidu Q3 model foundation, Vidu has been fully integrated across its product ecosystem, including Vidu Agent, Vidu Claw, and the Vidu App. This creates a unified system supporting the full workflow from creative ideation and content production to deployment, enabling greater efficiency and consistency across diverse use cases.
The release reflects ShengShu's broader progress in advancing its world model capabilities across digital environments.
In parallel with the product release, ShengShu announced it has raised RMB 2 billion in its Series B financing round, led by Alibaba Cloud, with participation from Andon Haitang, China Internet Investment Fund, TAL Education Group, Luminous Ventures, and others. Existing investors, including LINK-X CAPITAL, Delta Capital, and Baidu Ventures, also increased their investment.
The funding will support ShengShu's broader vision of building a general world model that bridges the digital and physical worlds. The company is advancing both its World Generation Model (WGM), which powers digital content creation through the Vidu model family, and its World Action Model (WAM), designed for physical-world interaction. Together, these systems aim to enable unified modeling, prediction, and action across environments.
ShengShu is among the first globally to pursue a unified world model architecture that connects digital and physical domains. At the core of this system is its Foundation World Model, which underpins both WGM and WAM.
Within this framework, the Vidu model family focuses on content generation and interaction in digital environments. It supports synchronized audio-visual generation, extended video duration, strong temporal and spatial consistency, and cinematic-quality visuals. Its proprietary reference-based video generation capability addresses consistency challenges in multi-subject video production.
At launch, Vidu Q3 ranked No.1 globally on the benchmark published by Artificial Analysis. It supports up to 16 seconds of synchronized audio and video generation, multi-shot composition and camera control, background music and sound effect generation, and multilingual dialogue. The launch of Reference-to-Video further expands its capabilities across visual effects, audio, and application scenarios.
Vidu is available to global developers, creators, and enterprises through both MaaS (Vidu API platform) and SaaS offerings, and has been integrated into Alibaba Cloud Model Studio to support text-to-video, image-to-video, and reference-to-video generation across industries including internet, advertising, film and animation, education, and cultural tourism.
Dr. Zhu Jun, Founder of ShengShu Technology, said:
"At its core, a world model gives AI a unified way to represent and predict the real world.
Video plays a critical role in this, as it naturally captures time, space, motion, and causality.
By building a unified model architecture, we aim to connect perception and action—creating a complete loop from understanding the world, to generating it, to acting within it, and ultimately making the world model a true bridge between the digital and physical worlds."
** This press release is distributed by PR Newswire through automated distribution system, for which the client assumes full responsibility. **
ShengShu Launches Vidu Q3 Reference-to-Video with Expanded Visual and Audio Capabilities