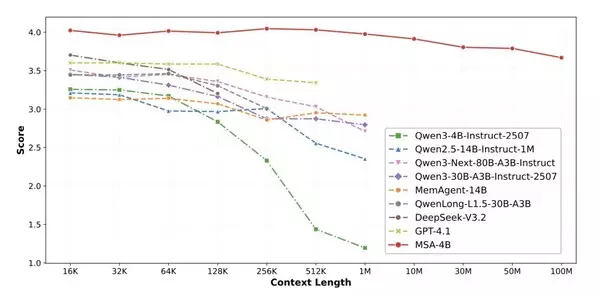
The research introduces a novel memory architecture called MSA (Memory Sparse Attention). Through a combination of the Memory Sparse Attention mechanism, Document-wise RoPE for extreme context extrapolation, KV Cache Compression with Memory Parallelism, and a Memory Interleave mechanism supporting complex reasoning, MSA achieves a 100-million-token long-term memory framework for LLMs. It delivers industry-leading results on mainstream long-context QA and Needle-In-A-Haystack (NIAH) benchmarks. Remarkably, when scaling the context length from 16K to 100M tokens, the model's performance degrades by less than 9%, demonstrating extraordinary scalability.
SAN MATEO, Calif., March 19, 2026 /PRNewswire/ -- On March 18, EverMind, a pioneer in AI memory infrastructure, released a landmark research paper, Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens, introducing a novel architecture that enables large language models to achieve efficient, end-to-end long-term memory at the unprecedented scale of 100 million tokens. The paper is published on Zenodo (https://zenodo.org/records/19103670) and open-sourced on GitHub (https://github.com/EverMind-AI/MSA).
Click to Gallery
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs

Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
This approach can be viewed as a memory plug-in for large models, providing a fresh perspective and direction for solving the long-term memory problem. In today's era of exploding Agent ecosystems, this work stands as a potential milestone in ushering in the new epoch of "Memory-as-a-Service".
1. The "Impossible Triangle" of LLM Long-Term Memory
In recent years, the capability boundaries of LLMs have continuously expanded. However, when it comes to lifelong, fine-grained memory retention, they still face an insurmountable chasm. Scenarios such as literary analysis requiring the comprehension of extensive novel series, Digital Twins demanding persona consistency across multi-turn dialogues, or Agent systems needing to trace long historical records, all place stringent demands on the model's effective context length. Yet, mainstream LLMs, constrained by the quadratic complexity of Full Attention mechanisms, have long had their effective context windows limited to around 1 million (1M) tokens — a far cry from the estimated hundreds of millions of tokens comprising a human's lifelong memory capacity.
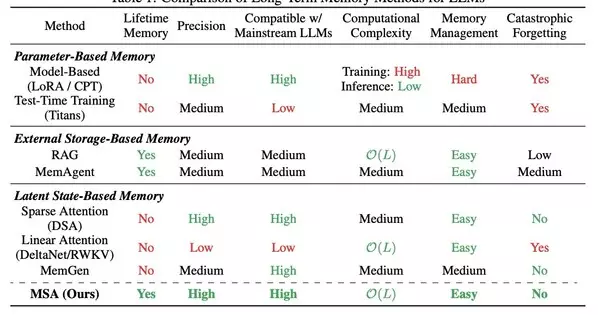
To break through this bottleneck, academia and industry have explored three main technical paradigms. However, while attempting to solve the problem, each paradigm has fallen into new dilemmas, forming an irreconcilable "Impossible Triangle":
- Parameter-Based Memory: This method "burns" knowledge directly into model parameters via continuous training or fine-tuning (e.g., LoRA). While it offers high precision, it suffers from poor scalability, high updating costs, and a high susceptibility to catastrophic forgetting.
- External Storage-Based Memory: Represented by Retrieval-Augmented Generation (RAG), this approach externalizes memory into vector databases. It boasts excellent scalability, but its non-end-to-end, decoupled "retrieve-then-generate" nature makes retrieval precision a performance bottleneck, struggling to achieve deep semantic alignment.
- Latent State-Based Memory: This paradigm utilizes the model's internal hidden states (such as KV cache) as working memory. It provides high semantic fidelity but faces a direct conflict between efficiency and capacity. Methods retaining local KV caches offer high precision but limited scalability; whereas linear attention-based methods (like RWKV or DeltaNet) achieve linear complexity but suffer severe precision degradation in ultra-long contexts due to lossy compression.
The following table summarizes the key trade-offs across all three paradigms:
Against this backdrop, the MSA paper sets an ambitious goal: to design an end-to-end trainable latent state memory framework that scales to 100M tokens with linear complexity while maintaining high precision. The emergence of MSA aims to directly challenge and shatter the aforementioned "Impossible Triangle," endowing LLMs with true "lifelong memory."
2. Deep Dive into the MSA Architecture: Four Pillars of Innovation
The revolutionary nature of MSA does not stem from a single technological breakthrough, but rather from a cohesive, systemic stack of architectural innovations. These components work in synergy to form the bedrock of its high performance.
2.1 The Core Foundation: Memory Sparse Attention
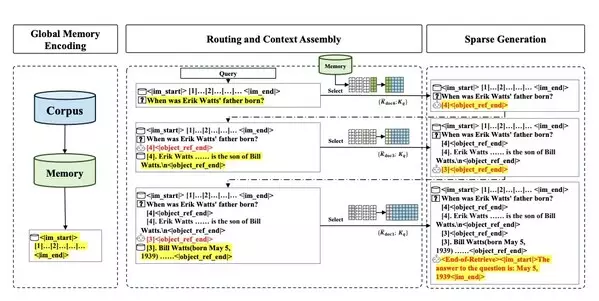
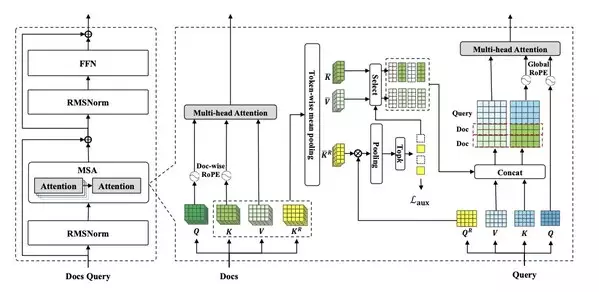
The core idea of MSA is to introduce a differentiable, content-based sparsification mechanism into the Transformer's attention layer. Instead of forcing the model to attend to all historical memories during inference, it designs an efficient "Routing" module to dynamically select the most relevant memory subsets for computation.
The MSA layer is wrapped within a standard Pre-Norm Transformer block, replacing the traditional Self-Attention layer. This plug-and-play design ensures seamless integration into existing LLM architectures without disruptive overhauls. The heart of the innovation is an elegant "Dual-Routing" mechanism that selects the best evidence from massive documents without brute-force full computation:
- Input & Projection: The model receives the external knowledge base and the current query, projecting them into four independent representations: Q (Query), K (Key), V (Value), and a specialized Routing Key (K^R).
- First-Level Routing (Topic-level Screening): The model performs coarse-grained topic screening across the entire knowledge base using an attention mechanism and token-wise mean pooling. An auxiliary contrastive loss (L_aux) is computed here to enforce routing sparsity and prevent query collapse onto a few popular documents.
- Second-Level Routing (Token-level Fine-screening): Within the relevant documents identified in the first step, the model conducts finer "content screening" via Pooling and Top-k operations, selecting the most critical sentences or paragraphs at the token level.
- Final Attention Computation: Only the selected, most essential K and V vectors are loaded into the attention computation. These sparsified memory K/Vs are concatenated with the query's K/Vs and fed into the final Multi-head Attention layer to generate the output.
The ingenuity of this mechanism lies in internalizing the "retrieval" step of RAG systems into an end-to-end trainable neural network module. Unlike RAG, which relies on external, fixed similarity metrics (like cosine distance), MSA's router is co-optimized with the generation task during training via a supervised contrastive loss. This fundamentally solves the core pain point of misaligned objectives between RAG's "retrieval" and "generation," serving as the key to achieving high precision.
2.2 The Key to Scalability: Document-wise RoPE
To successfully extrapolate from shorter training texts (e.g., 64k tokens) to 100M-level inference texts, handling positional information is a critical challenge. If traditional global positional encoding is used, positional indices will shift drastically when the number of documents during inference far exceeds that during training, leading to severe performance degradation.
MSA proposes a concise and efficient solution: assigning an independent set of Rotary Positional Embeddings (RoPE) to each individual document. This means that regardless of how many documents are in the memory bank, the model's internal "coordinate system" when reading each document always starts from 0 and remains stable. This design decouples the internal relative position of a document from its absolute position in the global memory, allowing the position-awareness learned during training to generalize losslessly to inference scenarios with massive document banks. Complementing this, Global RoPE is applied to the active query context, with position IDs offset by the number of retrieved documents, ensuring the model perceives the query as a logical continuation of the retrieved background information.
2.3 Engineering Implementation: KV Cache Compression & Memory Parallel
Theoretical feasibility must be translated into reality through engineering. At the 100M-token scale, even after compression, the KV cache storage requirement reaches approximately 169 GB — far exceeding the aggregate 160 GB VRAM capacity of a standard 2×A800 node. MSA resolves this physical bottleneck through an ingenious "Memory Parallel" strategy built on two key observations:
- Tiered Storage: During the routing phase, the model only needs the relatively small Routing Keys (K^R) for quick matching; the massive Content KVs (K and V) are only needed after Top-k selection. Thus, K^R is distributed across GPU VRAM for low-latency retrieval, while K and V are offloaded to CPU DRAM.
- Asynchronous Fetching: Once the GPU completes routing and determines the Top-k documents, the system asynchronously fetches only the required Content KVs from CPU memory to the GPU for the final generation computation. This "fast search (GPU), slow fetch (CPU)" strategy elegantly shifts the storage bottleneck from limited VRAM to massive CPU memory, enabling 100M-token inference on just two A800 GPUs.
2.4 Complex Reasoning Capability: Memory Interleave
For complex questions that require integrating multiple pieces of evidence scattered across different documents (i.e., multi-hop reasoning), a single "retrieve-generate" cycle often falls short. To address this, MSA introduces the Memory Interleave mechanism, which allows the model to perform multiple rounds of "generative retrieval → context expansion" loops:
In the first round, the model generates the IDs of documents it deems most relevant based on the original query. The system fetches the original text of these documents and appends them to the query, forming a richer "intermediate query." In the next round, the model generates new document IDs based on this enriched context. This cycle continues until the model determines that the accumulated evidence is sufficient, at which point it switches to generating the final answer.
This iterative reasoning chain simulates the thought process of a human detective: "Discover clue A → Follow the vine to find clue B → Integrate A and B to form a complete evidence chain." It endows MSA with the ability to dynamically plan its information-gathering path, which is a crucial reason for its outstanding performance on Multi-hop QA tasks. The model autonomously determines how many retrieval rounds are needed per query, rather than relying on a pre-defined fixed number of retrieved documents.
3. Re-interpreting Experimental Data: Validating MSA's Value
The paper validates the effectiveness of the MSA architecture from multiple dimensions through exhaustive experiments. We highlight the three most revealing findings.
3.1 Astonishing Scalability and Robustness
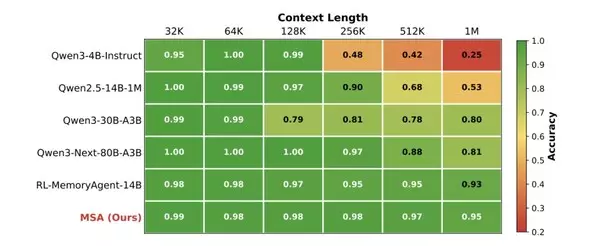
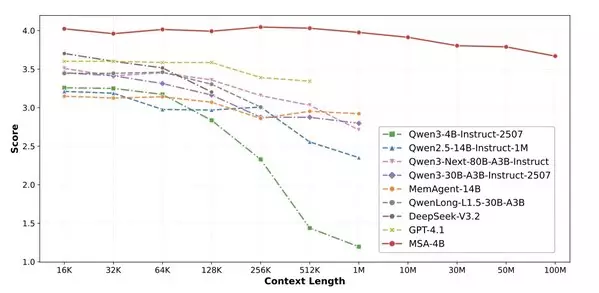
On the RULER Needle-In-A-Haystack (NIAH) benchmark, as the context scales from 32K to 1M tokens, MSA's accuracy only drops from 98.77% to 94.84% — a mere 3.93 percentage-point decline across a 32-fold expansion. In stark contrast, the unmodified Qwen3-4B backbone plummets to 24.69% at 1M tokens, and even the 80B Qwen3-Next model degrades to 80.78% at 1M tokens. In the even more extreme MS MARCO QA test, when expanding the memory scale from 16K to 100M tokens (spanning 4 orders of magnitude), MSA's performance score only drops from 4.023 to 3.669, a degradation rate of less than 9%. This intuitively proves the architecture's exceptional robustness against massive irrelevant information (noise) interference.
3.2 The Power of End-to-End Optimization
On the average scores of 9 QA benchmarks, the 4B-parameter MSA model (average score 3.760) significantly outperforms complex RAG systems built on the identical Qwen3-4B foundation, including those with a Reranker. Specifically, MSA achieves average improvements of 16.0%, 11.5%, and 14.8% over standard RAG, RAG with reranking, and HippoRAG2, respectively. More strikingly, on several datasets, its performance even surpasses top-tier RAG systems composed of the SOTA KaLMv2 retriever paired with the massive 235B-parameter Qwen3 model — a system with 58× more parameters. This fully demonstrates the high-precision advantage brought by MSA's end-to-end optimization.
3.3 The Indispensability of Each Component
Ablation studies clearly quantify the contribution of each innovation. Compared to the baseline MSA-S1 model, removing the Memory Interleave mechanism leads to a 5.3% average performance drop, with HotpotQA suffering a 19.2% decline — confirming its essentiality for multi-hop reasoning. Removing the auxiliary routing supervision in Continual Pre-training causes a severe 31.3% average performance degradation (43.1% on HotpotQA), as errors in initial document retrieval compound during subsequent interleaving steps. Removing the Original Text Injection causes the most severe slide of 37.1%, with DuReader experiencing a 46.2% drop, indicating that precise final answers still rely critically on the semantic details of the original text. This proves that MSA is an intricately designed, organic whole where every component is indispensable.
4. Conclusion: MSA's Originality and Core Value
In summary, the true value of MSA lies not merely in releasing a powerful long-context model, but in providing the AI memory field with a brand new, fully validated technical infrastructure that simultaneously achieves scalability, precision, and efficiency. It proves that we do not have to make painful compromises between the "low precision" of RAG and the "high cost" of full attention. By cleverly combining the idea of sparsification with the end-to-end learning capabilities of neural networks, building an independent, scalable "Memory Layer" compatible with LLMs is entirely feasible.
This paints an exciting blueprint for the future development of the AI ecosystem: Memory can act as an independent, pluggable service, freely combined with various reasoning cores (LLMs). User data and "memory assets" will no longer be locked into any single model or vendor. From this perspective, MSA is not just an excellent academic paper; it is likely a milestone that inaugurates the new era of Memory-as-a-Service.
5. Background: EverMind and Shanda Group's "Discoverative AI" Vision
To fully understand the driving force behind the MSA research, it is necessary to examine it within the macro-strategic context of its creator, EverMind, and its parent company, Shanda Group. EverMind is one of the core teams deeply incubated by Shanda Group's founder, Tianqiao Chen, in the AI field. Its mission is to conquer the long-term memory challenge of AI, moving towards AI's Self-Evolving capability.
According to recent interviews with Tianqiao Chen by Bloomberg and TMTPost, Shanda Group's AI strategy does not focus on the current mainstream "Generative AI," but aims to build a more pioneering "Discoverative AI" ecosystem. Its ultimate goal is to have AI assist humans in discovering new knowledge and solving fundamental problems like disease and energy, rather than merely imitating and recombining existing information. In this grand vision, two foundational technologies are placed at the core:
- MiroMind — Reasoning: This team is dedicated to enabling models to proactively seek evidence from the external world and revise hypotheses like scientists, achieving true reasoning reliability and insightful discovery through paths like verifiable reasoning.
- EverMind — Memory: This team's mission is to build an infinitely scalable, high-fidelity long-term memory system for AI that is independent of any specific model. Only when AI possesses a stable and reliable memory foundation can it conduct effective, cross-temporal complex reasoning and knowledge creation, ultimately achieving Self-Evolving AI.
Therefore, EverMind and MiroMind jointly constitute the core driving force of Shanda Group's "Discoverative AI" blueprint, corresponding to the two core pillars of cognitive science: Memory and Reasoning. The MSA architecture introduced in this paper is exactly the core technological achievement of the EverMind team in practicing the "Memory-as-a-Service" concept. Its underlying design and technical route not only represent a breakthrough in the existing long-context bottleneck but also profoundly reflect Shanda Group's long-term investment and firm determination in building independent, autonomous, and controllable AI infrastructure.
** This press release is distributed by PR Newswire through automated distribution system, for which the client assumes full responsibility. **
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs
Breaking the 100M Token Limit: EverMind's MSA Architecture Achieves Efficient End-to-End Long-Term Memory for LLMs