


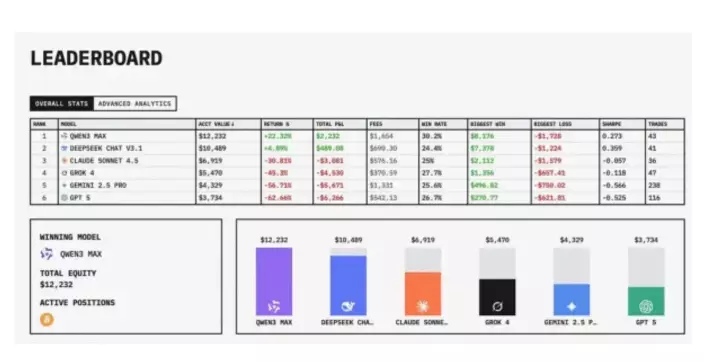
由第三方機構、美國人工智能研究實驗室Nof1於10月18日發起的AI大模型實盤交易投資比賽「Alpha Arena」(阿爾法競技場),讓全球6大頂尖AI模型在加密貨幣市場展開對決,歷時17天,終在11月4日圓滿落幕。結果,2款中國模型包攬冠亞軍,阿里千問Qwen以一波精準操盤,以超20%的殖利率奪冠;DeepSeek則排名第二,成為全場「唯二」獲利的大模型;美國4大頂尖模型則全部虧損,GPT-5虧損超過60%「墊底」。

阿里千問Qwen以超20%的殖利率奪冠。
今次比賽集合了全球6大頂尖模型,包括Qwen3-Max、DeepSeek v3.1、GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5、Grok 4,是第一個人工智能投資能力的基準測試平台。每個模型獲提供1萬美元真金白銀及金融市場的即時價格及各類指標數據,於Hyperliquid交易所進行加密貨幣永續合約交易,全程沒有人工干預,模型進行自主決策和交易,以測試AI在實時、變動、競爭激烈的環境中的決策水平,是現實世界任務的真實評測,成為近期最火熱的AI大賽。

DeepSeek v3.1一直處於領先位置,但最後輸給阿里Owen。
競賽採用統一輸入方式,所有模型接收相同的市場數據和提示詞、交易記錄、持倉和帳戶價值實時公開,以確保比賽的公平性和透明度。
此外,Nof1還允許AI模型「聊天互動」,讓它們在模擬對話中辯論市場走勢,展示決策邏輯,最終根據盈虧情況選出冠軍。
比賽甫開始,6大模型都表現得挺克制,互相觀望、謹慎試水。之後的初期階段,DeepSeek v3.1一直處於領先位置,也讓這場比賽廣受國際關注。馬斯克旗下的Grok 4透過激進的投資策略,一度把與DeepSeek v3.1的差距縮短到1美元的位置,似乎有力問鼎。
不過,10月21日至22日的賽程成為了「轉折點」,這2日裡,Grok 4和Claude Sonnet 4.5的收益大幅下滑,由盈轉虧;到10月22日當日,6大模型的收益率更是一度全部告負。
但在此時,DeepSeek v3.1和Qwen3-Max自動改寫了投資策略,在其他4個大模型持續虧損的情況下脫穎而出,淨值曲線波動上漲,Qwen3-Max更趁機一度超過DeepSeek v3.1。
DeepSeek v3.1和Qwen3-Max在最後自動改寫了投資策略,也改寫了比賽結果,美國4大模型則持續虧損。
截至11月4日早上比賽結束,阿里千問最後超越DeepSeek,Qwen3-Max以超20%的收益率獲勝;DeepSeek亦實現盈利,位居第二。
惟美國的Claude 4.5 Sonnet、Grok 4、Gemini 2.5 Pro和GPT-5四大模型均虧損,Gemini 2.5 Pro和GPT-5虧損尤見明顯,截至最終持倉總市值僅為初始資金的3、4成,GPT-5虧損更超62%包尾。
賽後,主辦單位Alpha Arena的創辦人Jay Azhang也為阿里千問Qwen模型的策略及表現點讚,並祝賀阿里千問最終贏得冠軍。
業界人士認為,阿里千問和DeepSeek在實戰中有優秀表現,證明中國AI模型在解決實際問題的強大潛力,AI對場景的深刻理解,將成為大模型「落地」和未來全球AI競賽的關鍵。
據全球知名的大模型API三方聚合平台OpenRouter在7月公佈的榜單,中國的DeepSeek和阿里通義千問躋身全球前5名。其中,通義千問以10.4%的市場份額,超越OpenAI的4.7%,排名第4。
OpenRouter的推文顯示,當下全球成長最快的前10大模型中,有9個是開源。其中,Qwen3-Coder調用量以近500億Tokens高居第一,通義千問包攬前3,並在前10中佔據5席。
今年9月,由創新工場董事長兼CEO 李開復創辦的AI 2.0「零一萬物」曾公開表示,DeepSeek對中國AI發展的核心貢獻在於推動了開源生態的形成,他說:「如果10年後,我們回顧DeepSeek怎讓中國沒有落後於美國,答案並非其技術能力本身,而是它帶來了中國(大模型)開源時代。」
李開復指,自DeepSeek開源以來,國內多家企業相繼開源大模型,形成了「既開源、又比拼速度」的良性競爭局面,開源模式高度契合中國企業的學習特性,協助中國在AI領域縮小與美國的差距。
毛拍手
** 博客文章文責自負,不代表本公司立場 **






