一項本地研究發現,人工智能(AI)在催眠減壓體驗上的成效可媲美真人催眠師,更有超過6成參與者表示更喜歡AI提供的體驗,反映AI或能成為降低心理支援門檻的有效工具。

研究發現更多人寧願對AI講心事。資料圖片
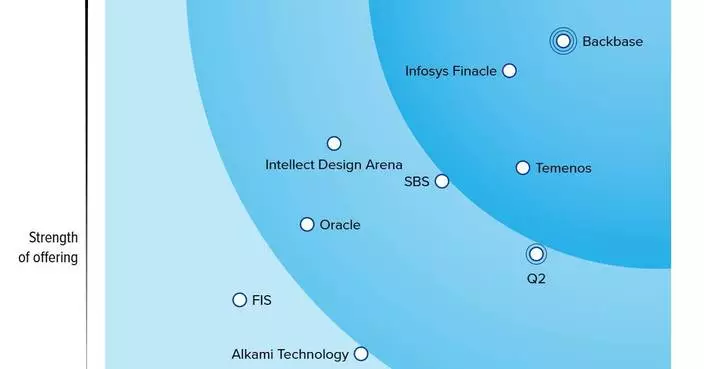
比較真人與AI催眠效果 400人報名
該項研究由AIM大中華區心理學研究小組於2025至2026年度進行,旨在比較真人催眠師與AI在催眠減壓上的實際成效。研究團隊透過社交媒體招募有家庭壓力的市民,帖子獲得逾400人主動報名,最終隨機邀請48人參與。每位參加者分別體驗兩段約一小時的催眠減壓錄音,一段由真人催眠師錄製,另一段則完全由AI生成文稿及聲音,其後比較兩者感受。
AI催眠體驗評分略高於真人
在關鍵的減壓效果比較上,比例最高的一組參加者(41.7%)認為AI與真人的效果「一樣」。若以評分計算,AI催眠體驗的平均分為2.92分,略高於真人體驗的2.58分。
研究亦指出,接近9成參加者表示,只要體驗後感到放鬆,便會喜歡該次體驗,顯示參與者更重視實際效果,而非提供者的身份。

被訪者認為AI表達方式清晰自然,不像面對真人時會擔心「講錯嘢」。資料圖片
逾6成偏好AI 因感「無壓力」
更值得留意的是,62.5%的參加者表示更喜歡AI的催眠體驗,其中女性群體的比例更高達68.4%;研究人員分析,這或與AI提供的「無壓力感」直接相關。
25%的參加者坦言,面對AI時更容易説出內心感受,原因是AI表達方式清晰自然,不像面對真人時會擔心「講錯嘢」或「被人評頭品足」。在私隱方面,超過5成參加者對AI處理個人資料感到放心,僅極少數(2.08%)表示不安。
AI看數據 治療師看人心
研究亦測試了AI作為分析工具的能力,AI能快速整理大量參與者的回應,客觀評估壓力狀況並找出規律。例如,AI從對話記錄中發現,35%的人不約而同地提到渴望「自己的空間」及希望「隔音好一點」,並將此現象與香港居住環境狹小的現實扣連,指出背後反映「連喘口氣的地方都沒有」的心理壓迫感。
此外,AI亦識別到不少參加者習慣在家中扮演「解決問題的人」或「調停角色」,長期壓抑情緒,這正是「長女壓力」及「夾心族」困境的體現。這種數據洞察有助治療師更快切入核心問題。
協作而非取代 助降低求助門檻
研究團隊強調,研究目的並非以AI取代真人治療師,而是探索兩者如何協作。團隊將AI類比為醫院中的驗血報告,能整理數據、發現規律、降低初期評估門檻,讓專業治療師能更專注於需要人情温度的介入部分。對於許多因怕麻煩、怕被標籤而卻步的人而言,AI或能成為鼓勵他們踏出尋求幫助第一步的橋樑。