人工智能基礎設施及液冷解決方案供應商凱圖斯(KAYTUS),在ISC 2026推出新一代智能基礎設施管理平台KSManage Ultra。該平台專為人工智能工廠而設,旨在為最新高密度人工智能機櫃提供統一智能管理。
「KSManage Ultra」可對運算托盤、交換機托盤、配電單元(PDU)及冷卻分配單元(CDU)等關鍵機櫃級組件,進行統一智能管理。透過端到端可視性、性能級診斷及自動化操作,該平台將高度耦合的人工智能基礎設施,從碎片化監管轉變為整合的系統級操作,協助企業構建更高效、可靠及可持續的人工智能基礎設施。

「KSManage Ultra」人工智能工廠專用。 AP圖片
凱圖斯指出,傳統人工智能操作面臨三大挑戰。首先,管理複雜性急劇上升。人工智能工廠的基本單位不再是單一伺服器,而是資源耦合的高密度人工智能機櫃。單一機櫃整合多個深度協調的子系統,包括運算、網絡、供電及液冷。與傳統4U 8個圖形處理器(GPU)部署相比,NVL72機櫃級系統整合近百個加速器及數千個高速互連。在100千瓦級機櫃中,功率密度可高出約兩至三倍,熱管理亦變得更複雜,涉及冷卻液分配、冷卻分配單元(CDU)、流量及相關安全控制。隨着人工智能工廠規模持續擴大,操作複雜性急劇增加,任何單一組件的波動都可能影響整個機櫃的性能及穩定性。
其次,故障識別已超越硬件層面。人工智能訓練及推理工作負載對性能波動高度敏感,隱藏異常可顯著降低操作效率。與傳統與停機相關的故障不同,人工智能系統的性能下降通常靜默發生。由於這些性能問題與底層硬件及基礎設施狀況密切相關,僅依賴來自工作負載或基礎設施的獨立數據,難以識別真正的根本原因。
第三,隨着部署規模擴大,人工智能工廠面臨日益嚴峻的操作效率危機。傳統逐個設備上線效率低下,減慢部署速度並增加配置不一致的風險。同時,傳統配置方法耗時且容易出錯。每個AI機櫃內整合多種設備類型,即使輕微配置偏差亦可能導致整個集群的性能下降或服務中斷。
凱圖斯表示,傳統操作模式依賴人手流程或碎片化工具,往往導致部署延遲、故障排除困難及配置不一致,限制人工智能應用程式的開發及大規模採用。為簡化人工智能數據中心的操作及管理,凱圖斯推出「KSManage Ultra」。該平台透過連接帶內及帶外管理路徑,並將資訊科技基礎設施狀態與實體基礎設施狀況關聯,實現跨組件、節點、機櫃、集群及數據中心層面的整個基礎設施堆棧整合管理。這代表操作從被動響應轉變為主動預警,協助客戶在複雜的人工智能工廠環境中,構建監控、診斷、故障隔離及全面恢復的智能操作能力。
「KSManage Ultra」提供人工智能數據中心操作狀態的單一視窗全球可視性,為傳統基礎設施及先進人工智能機櫃系統提供全堆棧統一管理。該平台為圖形處理器(GPU)、中央處理器(CPU)、記憶體、高速交換模組、管理網絡、電源架、冷卻分配單元(CDU)、液冷系統、機櫃及集群資源提供集中管理。透過打破資訊科技與實體基礎設施之間,以及單個組件與整個機櫃之間管理界限,「KSManage Ultra」創建跨組件、節點、機櫃、集群及整個數據中心的多層次資源視圖。
透過統一平台,客戶可避免重複切換多個系統,並快速評估資源健康狀況、機櫃可用性及集群準備狀態,以實現高效生產部署及操作。「KSManage Ultra」整合帶內數據(包括操作系統、驅動程式、應用程式及性能)與帶外數據(例如BMC、韌體、電源、溫度及硬件日誌),以及基礎設施數據到單一統一管理系統。它可實現跨操作狀態、硬件健康、鏈路拓撲、供電及液冷狀況的關聯分析,將操作從被動響應轉變為主動預警。當系統檢測到圖形處理器(GPU)異常、鏈路質量下降、液冷波動或節點健康狀況下降時,可主動識別有風險的節點,並引導客戶隔離、維護或重新配置資源,協助防止故障節點進入關鍵任務運行。
以液冷監控為例,「KSManage Ultra」支援節點、機櫃及迴路三級洩漏檢測。一旦檢測到洩漏風險,平台可協調安全關機、電磁閥關閉及節點隔離,同時觸發電郵警報、工單生成及閉環修復。這協助客戶為人工智能機櫃系統構建系統級主動操作能力。
「KSManage Ultra」專為多機櫃部署場景而設,提供資源健康識別及故障隔離能力。平台持續評估節點及機櫃健康狀況,基於圖形處理器(GPU)狀態、記憶體及PCIe狀態、網絡鏈路質量、韌體一致性、液冷狀況及供電狀態等指標。當檢測到異常節點或高風險組件時,系統可應用智能標記,分析潛在影響範圍,並啟動隔離操作,協助防止故障節點進入關鍵任務運行。
「KSManage Ultra」協助客戶建立清晰的可用資源視圖,包括應從服務中移除的節點、仍適合組合使用的機櫃、準備好用於訓練及推理工作負載的資源,以及應進入維護程序的資源。因此,客戶可超越故障發生後的被動修復,持續維持穩定的運算健康區,提高人工智能工廠的業務連續性及資源利用率。
「KSManage Ultra」支援一鍵批量掃描及自動添加節點。透過智能識別設備序列號及IP地址,平台自動建立節點與機櫃之間的拓撲映射,將單機櫃上線時間從傳統的50分鐘縮短至不足3分鐘。「KSManage Ultra」支援L10及L11級別的一鍵批量壓力測試,將故障根本原因定位時間從數小時縮短至數分鐘。平台亦可實現機櫃級自動化初始化及配置,包括驅動程式安裝、硬件配置及軟件部署,所有這些都可根據模板批量交付。透過顯著提高操作效率,同時協助維持同一集群內硬件環境的一致性,「KSManage Ultra」有效降低因配置漂移導致性能波動或任務失敗的風險。
作為人工智能工廠的全面統一平台,「KSManage Ultra」具備開放且高度兼容的架構。透過開放應用程式介面(API),它可無縫整合調度平台及配置管理數據庫(CMDB)等上層系統,同時亦提供伺服器、網絡設備、供電基礎設施及冷卻系統等下層異構設備的統一管理。這可實現整個數據中心環境的集中管理。「KSManage Ultra」旨在協助企業實現異構基礎設施的統一管理及智能操作,為人工智能工廠穩定高效運行奠定堅實基礎。
來源:
1. 傳統HGX H100/H200 4U 8個圖形處理器(GPU)伺服器每個42U機櫃通常支援4至8個單元,導致機櫃級功耗約為40至80千瓦。相比之下,GB200 NVL72機櫃可超120千瓦,功率密度約增加兩至三倍。
(美聯社)
KAYTUS作為人工智能(AI)基礎設施及液冷解決方案供應商,於ISC 2026展會上,發布其千兆瓦級、全預製集裝箱式液冷數據中心方案。該方案基於全廠預製模式,將數據中心標準化為三個模組化集裝箱單元,包括IT運算單元(IT Cube)、電力單元(Power Cube)及冷卻單元(Cooling Cube)。此設計實現IT、電力及冷卻系統的整合預製,支援更快部署及簡化項目執行。該架構可由3兆瓦基本單元,擴展至10兆瓦、15兆瓦、100兆瓦,以至高達1千兆瓦的AI工廠部署,並由KAYTUS提供單一供應商交付,涵蓋規劃、整合及營運。
阻礙歐盟AI工廠部署的三大主要挑戰
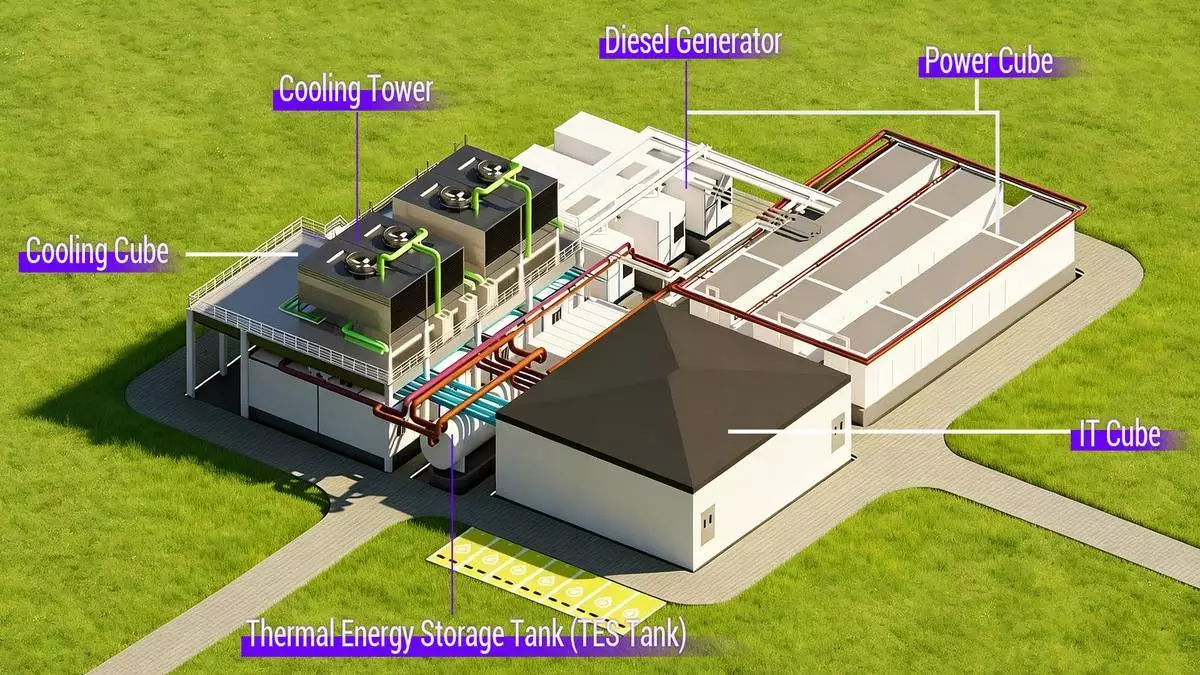
3兆瓦基本單元 AP圖片
歐盟的「AI工廠」倡議,正加速各成員國對主權AI基礎設施的需求,因運算部署正轉向大規模、高密度AI叢集,必須迅速部署、整合及投入運作。然而,依賴傳統數據中心建設模式的營運商,持續面臨三大挑戰:
部署速度已成為歐盟AI基礎設施項目的關鍵要求,營運商必須承擔高昂的圖像處理器(GPU)機架共置成本及龐大資本投資,以迅速投入運作並加速收入產生。另一方面,傳統數據中心建設通常需時18至24個月,電力、機械及冷卻系統往往由多個獨立供應商交付。這種分散的交付模式,可能導致供應商之間協調出現落差,造成進度延誤、成本超支及收入延遲實現。
建設品質難以標準化及控制,因各地區的本地建設能力差異甚大。熟練勞工往往有限且成本高昂,而傳統建設標準可能未能達到高密度AI系統的要求。此外,多工種現場施工,令結構、承重、電力及液冷系統難以保持一致品質,尤其對於支援高密度GPU機架系統的部署。
龐大前期資本承諾帶來重大部署風險,而分階段擴展可能產生基礎設施兼容性挑戰。若需求模式轉變,單一項目階段建設千兆瓦級AI基礎設施,需要大量資本開支,並增加閒置容量的風險。然而,分階段項目擴展,可能導致不同世代的電力、冷卻及設施基礎設施之間出現互操作性問題,令營運商需選擇前期過度投資,或日後承擔昂貴的改造及返工要求。
KAYTUS的差異化方案:三款標準化單元的全廠預製
與僅預製IT機架及液冷模組,而將機械及電氣基礎設施留待現場建設的方案不同,KAYTUS在工廠預製涵蓋IT、電力及冷卻系統的完整數據中心。該方案以三個標準化集裝箱模組交付,實現整合部署、提升系統一致性及加快投入運作時間。
IT運算單元:標準化、高密度運算基礎設施
IT運算單元採用雙層堆疊集裝箱架構,運算機架安裝在下層,整合的電力及數據佈線則經上層佈置。冷熱通道物理分離,以優化熱管理,而完整系統整合在工廠完成,以提升部署一致性及降低現場複雜性。
一個3兆瓦基本單元整合18個液冷運算機架、12個網絡機架、5個儲存機架及5個伺服器管理機架。每個液冷機架支援150千瓦電力密度,並設有明確升級路徑至200至227千瓦,以支援下一代AI加速器及高密度運算平台。冷卻分配單元(CDU)配置1+1冗餘,每單元提供1,200千瓦冷卻能力,支援高溫冷卻水運作,主側供水/回水溫度為攝氏35/45度,次側供水/回水溫度為攝氏40/45度。該系統亦整合標準三層脊葉核心網絡架構,允許多個3兆瓦單元互連,並作為統一AI叢集管理。次側液冷迴路、流量控制閥及洩漏檢測系統均在工廠完全整合。閥門控制可配置為手動操作、遙距電動控制或智能能源閥門管理,實現靈活的現場及遙距操作。
電力單元:冗餘、高可靠性電力基礎設施
電力傳輸單元(PTU)外殼及柴油發電機外殼獨立在工廠預製,以支援模組化電力部署。每個PTU額定功率為2,500千伏安,整合中壓變壓器、高低壓開關設備、高頻不間斷電源(UPS)系統,以及電網與發電機電源之間的自動轉換開關。配套的柴油發電機單元在付運前已完全組裝、整合及進行工廠測試。交付前完成全場景模擬測試,包括負載轉換開關及短路測試,有助確保電力可靠性、系統安全及加快現場調試。
完整的電力系統設計符合Uptime Institute Tier III級N+1可用性要求,採用2+1冗餘架構,以消除單點故障。若電網斷電,電池系統會橋接關鍵負載,同時柴油發電機啟動並接管供電,防止運算工作負載中斷。這可為高密度GPU叢集及關鍵AI工作負載,提供24小時不間斷運作。
冷卻單元:液冷部署的高效熱管理
冷卻單元整合兩個預製冷卻子系統:高溫液冷源及低溫風冷冷水機組,閉路冷卻塔安裝在外殼上層平台。液冷機組提供4,200千瓦冷卻能力,供水及回水溫度為攝氏35/45度,而冷水機組提供3,300千瓦冷卻能力,供水及回水溫度為攝氏18/24度。兩個子系統均整合冗餘水泵、水處理及壓力管理系統,以支援高可用性及運作穩定性。熱緩衝罐在電力事件後提供10分鐘備用冷卻,涵蓋發電機啟動時間,而72小時應急儲水則在供水中斷時支援持續冷卻。所有系統在付運前均在工廠進行壓力測試及故障轉移驗證,以降低現場調試風險。
快速部署、靈活擴展、一致品質、全生命週期支援
所有三種單元類型的全廠預製,從根本上重新定義AI數據中心的工程設計、整合及交付方式。透過將IT、電力及冷卻整合從施工現場轉移至受控的工廠環境,該模式可在部署速度、建設品質、資本效率及長期基礎設施靈活性方面,實現顯著提升。
加快收入實現時間是全預製模式的關鍵優勢。與傳統數據中心通常所需的18至24個月建設週期相比,預製單元架構可將部署時間縮短至約6至8個月,包括約一個月設計、三至五個月工廠製造及運輸,以及兩個月現場安裝及調試。
由於組裝、整合及系統級驗證在工廠完成,現場返工減至最少,調試風險亦降低。一個3兆瓦單元可在交付後一個月內投入運作,協助營運商加速收入產生、縮短回報週期及提高投資資本回報。
單一供應商問責制簡化項目執行並降低交付風險。KAYTUS根據單一合約提供端到端交付,涵蓋現場勘測、結構評估、水質評估、方案設計、工廠製造、貨運及清關、安裝、調試及持續營運支援。
這種單一聯絡點的整合交付模式,可降低項目管理開支、提高進度可預測性,並加強整個部署生命週期的問責制。
工廠控制的品質,確保跨部署的一致建設標準。所有單元模組均在受控工廠環境中,根據統一的工程及品質保證要求進行組裝、壓力測試及負載驗證。這種組裝精確度超越現場施工通常可達到的水平,並減少對可變本地施工勞工能力的依賴。
工廠預製方案有助從一開始就將液體洩漏、電氣故障及冷卻系統故障的風險降至最低。模組化架構亦允許單個單元進行維修或更換,而不會中斷整個叢集。整合的數據中心基礎設施管理(DCIM)監控,提供機架、配電、冷卻基礎設施及洩漏檢測系統的實時可視性,支援主動營運及更高系統可靠性。
增量擴展降低前期資本承諾,同時保留長期擴展靈活性。3兆瓦基本單元實現分階段部署,允許客戶從初始容量區塊開始,驗證運作,並隨著需求增長逐步擴展至100兆瓦或千兆瓦級AI基礎設施,而無需前期投入全部資本。由於電力及冷卻架構在不同部署世代中保持一致,擴展可在不對現有基礎設施進行重大修改或造成破壞性計劃維護窗口的情況下執行。這種方案特別適用於長週期AI基礎設施規劃,其中運算容量要求、GPU平台路線圖及客戶需求會隨時間不斷演變。
關於KAYTUS
KAYTUS是AI基礎設施及液冷解決方案的領先供應商,為雲端、AI、邊緣運算及其他新興應用,提供多元化創新、開放及環保產品。KAYTUS以客戶為中心,透過其適應性業務模式,靈活回應用戶需求。
(美聯社)